Introduction:
A lot of us heard the word cache and when you ask them about caching they give you a perfect answer but they don’t know how it is built, or on which criteria I should favor this caching framework over that one and so on, in this article we are going to talk about Caching, Caching Algorithms and caching frameworks and which is better than the other.
The Interview:
"Caching is a temp location where I store data in (data that I need it frequently) as the original data is expensive to be fetched, so I can retrieve it faster. "
That what programmer 1 answered in the interview (one month ago he submitted his resume to a company who wanted a java programmer with a strong experience in caching and caching frameworks and extensive data manipulation)
Programmer 1 did make his own cache implementation using hashtable and that what he only knows about caching and his hashtable contains about 150 entry which he consider an extensive data(caching = hashtable, load the lookups in hashtable and everything will be fine nothing else) so lets see how will the interview goes.
Interviewer: Nice and based on what criteria do you choose your caching solution?
Programmer 1 :huh, (thinking for 5 minutes) , mmm based on, on , on the data (coughing…)
Interviewer: excuse me! Could you repeat what you just said again?
Programmer 1: data?!
Interviewer: oh I see, ok list some caching algorithms and tell me which is used for what
Programmer 1: (staring at the interviewer and making strange expressions with his face, expressions that no one knew that a human face can do :D )
Interviewer: ok, let me ask it in another way, how will a caching behave if it reached its capacity?
Programmer 1: capacity? Mmm (thinking… hashtable is not limited to capacity I can add what I want and it will extend its capacity) (that was in programmer 1 mind he didn’t say it)
The Interviewer thanked programmer 1 (the interview only lasted for 10minutes) after that a woman came and said: oh thanks for you time we will call you back have a nice day
This was the worst interview programmer 1 had (he didn’t read that there was a part in the job description which stated that the candidate should have strong caching background ,in fact he only saw the line talking about excellent package ;) )
Talk the talk and then walk the walk
After programmer 1 left he wanted to know what were the interviewer talking about and what are the answers to his questions so he started to surf the net, Programmer 1 didn’t know anything else about caching except: when I need cache I will use hashtable
After using his favorite search engine he was able to find a nice caching article and started to read.
Why do we need cache?
Long time ago before caching age user used to request an object and this object was fetched from a storage place and as the object grow bigger and bigger, the user had spend more time to fulfill his request, it really made the storage place suffer a lot coz it had to be working for the whole time this caused both the user and the db to be angry and there were one of 2 possibilities
1- The user will get upset and complain and even wont use this application again(that was the case always)
2- The storage place will pack up its bags and leave your application , and that made a big problems(no place to store data) (happened in rare situations )
Caching is a god sent:
After few years researchers at IBM (in 60s) introduced a new concept and named it “Cache”
What is Cache?
Caching is a temp location where I store data in (data that I need it frequently) as the original data is expensive to be fetched, so I can retrieve it faster.
Caching is made of pool of entries and these entries are a copy of real data which are in storage (database for example) and it is tagged with a tag (key identifier) value for retrieval.
Great so programmer 1 already knows this but what he doesn’t know is caching terminologies which are as follow:
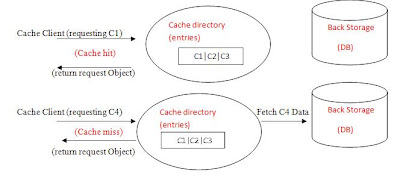 Cache Hit:
Cache Hit:
When the client invokes a request (let’s say he want to view product information) and our application gets the request it will need to access the product data in our storage (database), it first checks the cache.
If an entry can be found with a tag matching that of the desired data (say product Id), the entry is used instead. This is known as a cache hit (cache hit is the primary measurement for the caching effectiveness we will discuss that later on).
And the percentage of accesses that result in cache hits is known as the hit rate or hit ratio of the cache.
Cache Miss:
On the contrary when the tag isn’t found in the cache (no match were found) this is known as cache miss , a hit to the back storage is made and the data is fetched back and it is placed in the cache so in future hits it will be found and will make a cache hit.
If we encountered a cache miss there can be either a scenarios from two scenarios:
First scenario: there is free space in the cache (the cache didn’t reach its limit and there is free space) so in this case the object that cause the cache miss will be retrieved from our storage and get inserted in to the cache.
Second Scenario: there is no free space in the cache (cache reached its capacity) so the object that cause cache miss will be fetched from the storage and then we will have to decide which object in the cache we need to move in order to place our newly created object (the one we just retrieved) this is done by replacement policy (caching algorithms) that decide which entry will be remove to make more room which will be discussed below.
Storage Cost:
When a cache miss occurs, data will be fetch it from the back storage, load it and place it in the cache but how much space the data we just fetched takes in the cache memory? This is known as Storage cost
Retrieval Cost:
And when we need to load the data we need to know how much does it take to load the data. This is known as Retrieval cost
Invalidation:
When the object that resides in the cache need is updated in the back storage for example it needs to be updated, so keeping the cache up to date is known as Invalidation.
Entry will be invalidate from cache and fetched again from the back storage to get an updated version.
Replacement Policy:
When cache miss happens, the cache ejects some other entry in order to make room for the previously uncached data (in case we don’t have enough room). The heuristic used to select the entry to eject is known as the replacement policy.
Optimal Replacement Policy:
The theoretically optimal page replacement algorithm (also known as OPT or Belady’s optimal page replacement policy) is an algorithm that tries to achieve the following: when a cached object need to be placed in the cache, the cache algorithm should replace the entry which will not be used for the longest period of time.
For example, a cache entry that is not going to be used for the next 10 seconds will be replaced by an entry that is going to be used within the next 2 seconds.
Thinking of the optimal replacement policy we can say it is impossible to achieve but some algorithms do near optimal replacement policy based on heuristics.
So everything is based on heuristics so what makes algorithm better than another one? And what do they use for their heuristics?
Nightmare at Java Street:
While reading the article programmer 1 fall a sleep and had nightmare (the scariest nightmare one can ever have)
Programmer 1: nihahha I will invalidate you. (Talking in a mad way)
Cached Object: no no please let me live, they still need me, I have children.
Programmer 1: all cached entries say that before they are invalidated and since when do you have children? Never mind now vanish for ever.
Buhaaahaha , laughed programmer 1 in a scary way, ,silence took over the place for few minutes and then a police serine broke this silence, police caught programmer 1 and he was accused of invalidating an entry that was still needed by a cache client, and he was sent to jail.
Programmer 1 work up and he was really scared, he started to look around and realized that it was just a dream then he continued reading about caching and tried to get rid of his fears.
Caching Algorithms:
No one can talk about caching algorithms better than the caching algorithms themselves
Least Frequently Used (LFU):
I am Least Frequently used; I count how often an entry is needed by incrementing a counter associated with each entry.
I remove the entry with least frequently used counter first am not that fast and I am not that good in adaptive actions (which means that it keeps the entries which is really needed and discard the ones that aren’t needed for the longest period based on the access pattern or in other words the request pattern)
Least Recently Used (LRU):
I am Least Recently Used cache algorithm; I remove the least recently used items first. The one that wasn’t used for a longest time.
I require keeping track of what was used when, which is expensive if one wants to make sure that I always discards the least recently used item.
Web browsers use me for caching. New items are placed into the top of the cache. When the cache exceeds its size limit, I will discard items from the bottom. The trick is that whenever an item is accessed, I place at the top.
So items which are frequently accessed tend to stay in the cache. There are two ways to implement me either an array or a linked list (which will have the least recently used entry at the back and the recently used at the front).
I am fast and I am adaptive in other words I can adopt to data access pattern, I have a large family which completes me and they are even better than me (I do feel jealous some times but it is ok) some of my family member are (LRU2 and 2Q) (they were implemented in order to improve LRU caching
Least Recently Used 2(LRU2):
I am Least recently used 2, some people calls me least recently used twice which I like it more, I add entries to the cache the second time they are accessed (it requires two times in order to place an entry in the cache); when the cache is full, I remove the entry that has a second most recent access. Because of the need to track the two most recent accesses, access overhead increases with cache size, If I am applied to a big cache size, that would be a problem, which can be a disadvantage. In addition, I have to keep track of some items not yet in the cache (they aren’t requested two times yet).I am better that LRU and I am also adoptive to access patterns.
-Two Queues:
I am Two Queues; I add entries to an LRU cache as they are accessed. If an entry is accessed again, I move them to second, larger, LRU cache.
I remove entries a so as to keep the first cache at about 1/3 the size of the second. I provide the advantages of LRU2 while keeping cache access overhead constant, rather than having it increase with cache size. Which makes me better than LRU2 and I am also like my family, am adaptive to access patterns.
Adaptive Replacement Cache (ARC):
I am Adaptive Replacement Cache; some people say that I balance between LRU and LFU, to improve combined result, well that’s not 100% true actually I am made from 2 LRU lists, One list, say L1, contains entries that have been seen only once “recently”, while the other list, say L2, contains entries that have been seen at least twice “recently”.
The items that have been seen twice within a short time have a low inter-arrival rate, and, hence, are thought of as “high-frequency”. Hence, we think of L1as capturing “recency” while L2 as capturing “frequency” so most of people think I am a balance between LRU and LFU but that is ok I am not angry form that.
I am considered one of the best performance replacement algorithms, Self tuning algorithm and low overhead replacement cache I also keep history of entries equal to the size of the cache location; this is to remember the entries that were removed and it allows me to see if a removed entry should have stayed and we should have chosen another one to remove.(I really have bad memory)And yes I am fast and adaptive.
Most Recently Used (MRU):
I am most recently used, in contrast to LRU; I remove the most recently used items first. You will ask me why for sure, well let me tell you something when access is unpredictable, and determining the least most recently used entry in the cache system is a high time complexity operation, I am the best choice that’s why.
I am so common in the database memory caches, whenever a cached record is used; I replace it to the top of stack. And when there is no room the entry on the top of the stack, guess what? I will replace the top most entry with the new entry.
First in First out (FIFO):
I am first in first out; I am a low-overhead algorithm I require little effort for managing the cache entries. The idea is that I keep track of all the cache entries in a queue, with the most recent entry at the back, and the earliest entry in the front. When there e is no place and an entry needs to be replaced, I will remove the entry at the front of the queue (the oldest entry) and replaced with the current fetched entry. I am fast but I am not adaptive
-Second Chance:
Hello I am second change I am a modified form of the FIFO replacement algorithm, known as the Second chance replacement algorithm, I am better than FIFO at little cost for the improvement. I work by looking at the front of the queue as FIFO does, but instead of immediately replacing the cache entry (the oldest one), i check to see if its referenced bit is set(I use a bit that is used to tell me if this entry is being used or requested before or no). If it is not set, I will replace this entry. Otherwise, I will clear the referenced bit, and then insert this entry at the back of the queue (as if it were a new entry) I keep repeating this process. You can think of this as a circular queue. Second time I encounter the same entry I cleared its bit before, I will replace it as it now has its referenced bit cleared. am better than FIFO in speed
-Clock:
I am Clock and I am a more efficient version of FIFO than Second chance because I don’t push the cached entries to the back of the list like Second change do, but I perform the same general function as Second-Chance.
I keep a circular list of the cached entries in memory, with the "hand" (something like iterator) pointing to the oldest entry in the list. When cache miss occurs and no empty place exists, then I consult the R (referenced) bit at the hand's location to know what I should do. If R is 0, then I will place the new entry at the "hand" position, otherwise I will clear the R bit. Then, I will increment the hand (iterator) and repeat the process until an entry is replaced.I am faster even than second chance.
Simple time-based:
I am simple time-based caching; I invalidate entries in the cache based on absolute time periods. I add Items to the cache, and they remain in the cache for a specific amount of time. I am fast but not adaptive for access patterns
Extended time-based expiration:
I am extended time based expiration cache, I invalidate the items in the cache is based on relative time periods. I add Items the cache and they remain in the cache until I invalidate them at certain points in time, such as every five minutes, each day at 12.00.
Sliding time-based expiration:
I am Sliding time-base expiration, I invalidate entries a in the cache by specifying the amount of time the item is allowed to be idle in the cache after last access time. after that time I will invalidate it . I am fast but not adaptive for access patterns
Ok after we listened to some replacement algorithms (famous ones) talking about themselves, some other replacement algorithms take into consideration some other criteria like:
Cost: if items have different costs, keep those items that are expensive to obtain, e.g. those that take a long time to get.
Size: If items have different sizes, the cache may want to discard a large item to store several smaller ones.
Time: Some caches keep information that expires (e.g. a news cache, a DNS cache, or a web browser cache). The computer may discard items because they are expired. Depending on the size of the cache no further caching algorithm to discard items may be necessary.
The E-mail!
After programmer 1 did read the article he thought for a while and decided to send a mail to the author of this caching article, he felt like he heard the author name before but he couldn’t remember who this person was but anyway he sent him mail asking him about what if he has a distributed environment? How will the cache behave?
The author of the caching article got his mail and ironically it was the man who interviewed programmer 1 :D, The author replied and said :
Distributed caching:
*Caching Data can be stored in separate memory area from the caching directory itself (who handle the caching entries and so on) can be across network or disk for example.
*Distrusting the cache allows increase in the cache size.
*In this case the retrieval cost will increase also due to network request time.
*This will also lead to hit ratio increase due to the large size of the cache
But how will this work?
Let’s assume that we have 3 Servers, 2 of them will handle the distributed caching (have the caching entries), and the 3rd one will handle all the requests that are coming (Which asks about cached entries):
Step 1: the application requests keys entry1, entry2 and entry3, after resolving the hash values for these entries, and based on the hashing value it will be decided to forward the request to the proper server.
Step 2: the main node sends parallel requests to all relevant servers (which has the cache entry we are looking for).
Step 3: the servers send responses to the main node (which sent the request in the 1st place asking to the cached entry).
Step 4: the main node sends the responses to the application (cache client).
*And in case the cache entry were not found (the hashing value for the entry will be still computed and will redirect either to server 1 or server 2 for example and in this case our entry wont be found in server 1 so it will fetched from the DB and added to server 1 caching list.

Measuring Cache:
Most caches can be evaluated based on measuring the hit ratio and comparing to the theoretical optimum, this is usually done by generation a list of cache keys with no real data, but here the hit ratio measurement assumes that all entries have the same retrieval cost which is not true for example in web caching the number of bytes the cache can server is more important than the number of hit ration (for example I can replace the big entry will 10 small entries which is more effective in web)
Conclusion:
We have seen some of popular algorithms that are used in caching, some of them are based on time, cache object size and some are based on frequency of usage, next part we are going to talk about the caching framework and how do they make use of these caching algorithms, so stay tuned ;)
Related Articles:
Part 2 (Algorithm Implementation)
Part 3 (Algorithm Implementation)
Part 4 (Frameworks Comparison)
Part 5 (Frameworks Comparison)




{kind=link}
57 comments:
This is a very nice post, very informative and organized.
Thank u for knowledge sharing :)
Hi Hossam ,
am glad you liked it :) thank you for commenting and hope you will like part 2.
Ahmed, thanks for the effort, keep it up.
I think you could structure it slightly differently: if you could keep the actual content - the useful technical information about caching - flowing without these artistic interruptions (e.g. Programmer 1 said: "bwahaha"), it would have been much easier to read through. The examples are useful, I would say, to beginners; the professional people are able to understand sophisticated technical texts without the dramatization.
This is probably because of the blog format that you chose, but in a book you could box those examples off, so that those who need them could peek at them.
Thanks
Stas
Stas,
Thanks you so much for your feedback i really appreciate it so much
Thanks,
Ahmed
Thanks for the article Ahmed. I like the dramatization as dry technical articles sometimes get boring. The creativity in your writing is a good thing IMHO. It keeps something that could get really boring from getting "too" boring. However, I agree that if you were to use this in the context of a technical publication that you should probably cut out the drama.
As for the content of the article...I'd like to see some code samples...even if they're simple. It would be interesting to see even something as simple as a reimplementation of a database object that knew how to keep itself updated in some sort of cache. Maybe show the differences in the implementation of the algorithms you discussed.
Thanks again,
Chris
Chris,
thanks for you feedback i really appriciate it , for code sample just wait till part 2 ;) hope you will like it :)
Thanks,
Ahmed
I love it ahmed, very informative post. very helpful
AG,
Thanks for your comment , i am glad you liked it :) , hope you will like the 2nd part also ;)
Hi Ahmed, nice article quite informative. Thanks for all the detailed information.
One thing I would suggest is that you could have mentioned some of the open-source caching systems like JBoss Cache, EhCache, etc. Also Terracota http://www.terracotta.org/. Though it says its a clustering framework, it gives you replication capabilities that are implemented though JVM heap.
Shashikant,
Thank you so much for your comment, i will have something like this in part 2 or maybe part 3 ;) between OSCache,EHCache,JSC ,... hopfully you will like it :) , thanks again for your comment
Thanks
Ahmed ALi
Hello there,
I really enjoyed your article; the use of first-person perspective describing the removal policy was surprisingly effective at hammering the information into my head. good work!
Patrick,
Thanks for your comment ,am glad you liked the article and hpe you will like part 2 also
It was really great. Very well useful and organized article.
Dramatization is also not problem for me, because this is your style.
There could be informative visual diagrams about each algorithms, but it is still wonderful.
Thanks.
Cemo,
Thank you so much for your feedback and comment.
i really appriciate it,and next time i will try to put more diagram , in part 2 ;)
Thanks.
boy didn't i enjoy this article !!
very good thanks
narup,
Thanks for your comment , am glad you enjoyed the article
Thanks.
جزاك الله خيرا على هذه المعلومات
AhmedAdel,
am glad you liked it , hope you will like part 2 also
Thanks.
Gr8 stuff. Maybe in the next part you will have a chance to discuss various data formats that can be stored in cache. For sure there are some advantages and disadvantages of storing native objects (ex. java in jboss pojocache) and their string representation (json, xml in memcached).
I am wondering what is the overhead of the serialization and deserialization. Maybe you will have a chance to touch upon that.
Cheers!
erace,
sure i will take it into consideration :) , thanks a lot for commenting and for your feedback :)
Thanks
I am impressed. Great Article. Very Informative. Great Work Buddy.
Mukesh,
Thank you for your comment :)
Great article. Keep it up.
Minor typo
"The storage place will backup its bags"
Should be
"The storage place will pack up its bags"
Thanks for the correction :)
Hi Ahmed,
Interesting series of articles, thanks.
You might be interested to look at a recently open-sourced set of code I've been working on called custard-cache -- it's a Java implementation of several caches (currently FIFO, LRU, LFU, MQ, ARC, FRC, and 2Q, along with a very trivial Direct Mapped cache purely as an example). Look at the CacheManager class hierarchy for the policy implementations.
I'm working on adapters to enable these policies to be plugged in to JBoss cache, EHCache, etc. The project is in early days but if you're interested I'd love for you to check it out and let me know what you think.
Great article.
My experience is that you often don't need to sweat over cache replacement algorithms: sometimes simple and stupid things give great results.
I wrote a batch processing script which had to handle 10 billion records. It spent a lot of time doing database lookups: of course there was a long-tail distribution of keys being looked up and a lot of locality.
I stuffed the database results into a hashtable: this sped up the script five times, but would have caused an out-of-memory condition on the complete dataset. I added something that erased the whole hashtable once it accumulated a million items.
This replacement policy worked well in practice: I could have spent time thinking about my replacement policy -- this might have sped me up another 1% or let me cut the memory consumption a lot. The latter would matter under some circumstances, but not on my beefy 64-bit machine.
Paul,
Thanks for this nice comment, i agree with you that sometimes you don’t need to go for replacement algorithm and use simple solutions instead you even can come with a better approach but this depends on your design, business and also the hardware you will use for example the place that we are going to store cache data in like memory, disk for example.
So in the end it all depends on your design and your business need beside the hardware you are going to run your application on ;) but as you said:
'Sometimes simple and stupid things give great results.'
Thank you. It is a great article!
Alexandro,
Thanks for your nice comment
FYI, ARC caching policy is patented by IBM and therefore is not a good caching policy to choose if you are worried about legal problems. CLOCK-2 would be a good replacement.
Peter,
Thanks for your comment , it turned out that there would be a legal problems if you choose ARC which is patented by IBM(thanks for highlighting that), i am assuming that Clock-2 is Clock-pro replacemnt polecy,if so yea its performance is better than LRU or Clock policy.
Thank you
Ahmed, check out this PDF on the research on CLOCK-PRO. This policy replaced the use of ARC in Postgres database.
http://www.cse.ohio-state.edu/hpcs/WWW/HTML/publications/papers/TR-05-3.pdf
Peter,
Thank you so much for your comment and resources, i checked the PDF and also checked PostgreSQL legal problems with IBM ARC that happend in postgreSQL 8.0 and 8.1 release
Thanks
Nice post Ahmed. The readers can also expand their knowledge on the subject by going here
Kevin,
Thanks fo your comment and for the link (i didnt review it yet but am sure it will be very helpfull for .net Guys(i was one of them few years ago ;) )
Thanks,
very nice post, I like it.
Haytham,
thanks for your comment glad you liked it and wait for the comming parts
Thanks,
very nice article! I learned lots of things about caching in such a short time! Kudos!!
Kajari,
thanks for commenting , glad you liked the article hope yould enjoy reading the other parts ;)
Thanks,
我翻译了一部分,http://leizi999.blogspot.com/2009/05/blog-post.html。(水平有限,看官多包涵)。谢谢。
leizi,
Xie Xie ni :D , thank you so much for your translation effort hope you enjoyed the post :)
Thanks,
Hello,
Thanks a lot for your nice comment :)
Hi, Ahmed.
I think it would be interesting to cover some variations on LFU, such as Aging:
http://en.wikipedia.org/wiki/Page_replacement_algorithm#Aging
Aging certainly makes LFU a much more interesting competitor to traditional LRU in cases where both frequency and recency are significant.
Hi Shawn,
Thanks a lot for your comment and for highlighting the aging technique, what if you have only 16bit so the counter will be set to 0again so we don’t have a way to know if this page was last referenced 17 clock tick ago or 20 clock tick ago for example but in general i go with you that it compete with LRU algorithm, thanks a lot for your comment and for the highlighting
Thanks,
Ahmed Ali
Thanks for great information.
Cheap web design services
Excellent post. Many thanks for sharing this useful resource on "Caching".
Hi Ahmed!
This was a very nice blog.
As i was new to this topic,i really
liked the way u dramatized it.
Otherwise i went through lods of blogs...i had completely lost interest because of them.
Would like to see the block of code too!!
good work!!
Hi Ahmed!
This was a very nice blog.
As i was new to this topic,i really
liked the way u dramatized it.
Otherwise i went through lods of blogs...i had completely lost interest because of them.
Would like to see the block of code too!!
good work!!
Hi Richie,
i am glad you liked it :) and hopefully i will release another part for distributed caching so stay tuned
Thanks
dear,
thank you very much for your information series "Intro to Caching,Caching algorithms and caching frameworks part 1".actually very hard to find this type information.very useful.
Sweet
pick up lines
a good text. Not so boring as many other texts.
Was definitely useful stuff!
Thanks a lot man.
Thanks
I liked it.Really informative in a very high level.Thnx.
Hi Ahmed,
2 things to appreciate.
1. The technical details on cache provided is the best way explained. No pulp just Juice.
2. The way the interview and after interview things narrated added good fun.
Just few days back i had been the "programmer 1". With in interview and after interview the happenings are just as you given. No change.
Learnt a lot from this article ... really. Able to laugh on my own mistakes like anything after reading this. Great work.
Keep it up.
Really a Great and informative article.
Superb article !!!
Post a Comment